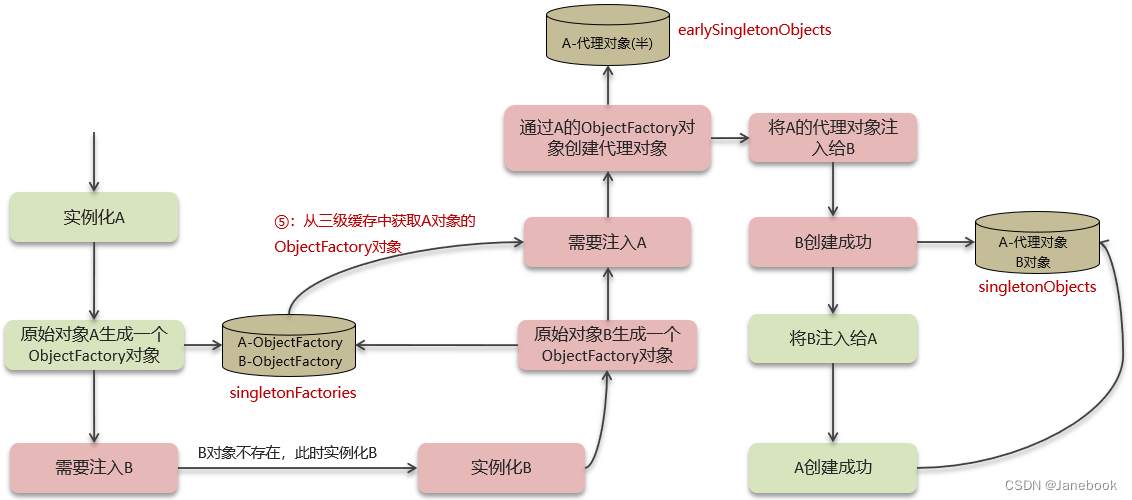
jdk6,7,8三个版本的内存模型

如图所示 JDK 1.6、1.7、1.8 的内存模型演变过程,其实这个内存模型就是 JVM 运行时数据区依照JVM虚拟机规范的具体实现过程。
- JDK 1.6:程序计数器、Java虚拟机栈、本地方法栈、堆、方法区[永久代](字符串常量池、静态变量、运行时常量池、类常量池)
- JDK 1.7:程序计数器、Java虚拟机栈、本地方法栈、堆(字符串常量、静态变量)、方法区[永久代](运行时常量池、类常量池)
- JDK 1.8:程序计数器、Java虚拟机栈、本地方法栈、堆(字符串常量)、元数据(静态变量、运行时常量池、类常量池)
JDK 1.8 JVM 的内存结构主要由三大块组成:堆内存、元空间和栈,Java 堆是内存空间占据最大的一块区域。
Java 堆,由年轻代和年老代组成,分别占据1/3和2/3。
年轻代又分为三部分,Eden、From Survivor、To Survivor,占据比例为8:1:1,可调。
元空间从虚拟机Java堆中转移到本地内存,默认情况下,元空间的大小仅受本地内存的限制,说白了也就是以后不会因为永久代空间不够而抛出OOM异常出现了。jdk1.8以前版本的 class和JAR包数据存储在 PermGen下面 ,PermGen 大小是固定的,而且项目之间无法共用,公有的 class,所以比较容易出现OOM异常。
升级JDK 1.8后,元空间配置参数,-XX:MetaspaceSize=512M XX:MaxMetaspaceSize=1024M。小技巧通过jps、jinfo查看元空间,如下:
通过jinfo查看默认MetaspaceSize大小(约20M),MaxMetaspaceSize比较大。
其他:关于JDK1.8 元空间的介绍: Move part of the contents of the permanent generation in Hotspot to the Java heap and the remainder to native memory. http://openjdk.java.net/jeps/122
JDK1.8为什么要移除方法区
1)永久代来存储类信息、常量、静态变量等数据不是个好主意, 很容易遇到内存溢出的问题.JDK8的实现中将类的元数据放入 native memory, 将字符串池和类的静态变量放入java堆中. 可以使用MaxMetaspaceSize对元数据区大小进行调整;
2)对永久代进行调优是很困难的,同时将元空间与堆的垃圾回收进行了隔离,避免永久代引发的Full GC和OOM等问题;
jvm内存c参数设置参考:
JVM内存参数设定
-Xms 初始堆内存大小
-Xmx 最大堆内存大小
-Xss 单个线程栈大小
-XX:NewSize 初始新生代堆大小
-XX:MaxNewSize 生代最大堆大小
-XX:PermSize 方法区初始大小(JDK1.7及以前)
-XX:MaxPermSize 方法区最大大小(JDK1.7及以前)
-XX:MetaspaceSize 元数据区初始值(JDK1.8)
-XX:MaxMetaspaceSize 元数据区最大值(JDK1.8)
参数设置示例
jdk1.7 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.7 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256mJDK各个版本中JVM-GC的变化
jdk7和jdk8的默认垃圾收集器实现:Parallel Scavenge(新生代)+Parallel Old(老年代)。
JDK9: 设置G1为JVM默认垃圾收集器
JDK10:并行全垃圾回收器 G1,通过并行Full GC, 改善G1的延迟。目前对G1的full GC的实现采用了单线程-清除-压缩算法。JDK10开始使用并行化-清除-压缩算法。
JDK11:推出ZGC新一代垃圾回收器(实验性),目标是GC暂停时间不会超过10ms,既能处理几百兆的小堆,也能处理几个T的大堆。
JDK14 :删除CMS垃圾回收器;弃用 ParallelScavenge + SerialOld GC 的垃圾回收算法组合;将 zgc 垃圾回收器移植到 macOS 和 windows 平台
JDk 15 : ZGC (JEP 377) 和Shenandoah (JEP 379) 不再是实验性功能。默认的 GC 仍然是G1。
JDK16:增强ZGC,ZGC获得了 46个增强功能 和25个错误修复,控制stw时间不超过10毫秒GC(垃圾收集器)
新生代收集器使用的收集器:Serial、PraNew、Parallel Scavenge
老年代收集器使用的收集器:Serial Old、Parallel Old、CMS
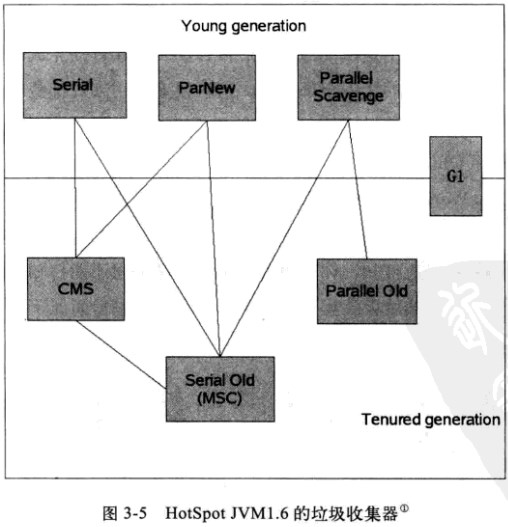
Serial收集器(复制算法)
新生代单线程收集器,标记和清理都是单线程,优点是简单高效。
Serial Old收集器(标记-整理算法)
老年代单线程收集器,Serial收集器的老年代版本。
ParNew收集器(停止-复制算法)
新生代收集器,可以认为是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现。
Parallel Scavenge收集器(停止-复制算法)
并行收集器,追求高吞吐量,高效利用CPU。吞吐量一般为99%, 吞吐量= 用户线程时间/(用户线程时间+GC线程时间)。适合后台应用等对交互相应要求不高的场景。
Parallel Old收集器(停止-复制算法)
Parallel Scavenge收集器的老年代版本,并行收集器,吞吐量优先
CMS(Concurrent Mark Sweep)收集器(标记-清理算法)
高并发、低停顿,追求最短GC回收停顿时间,cpu占用比较高,响应时间快,停顿时间短,多核cpu 追求高响应时间的选择
GC的执行机制
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。
Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个堆进行回收,所以比Scavenge GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC:
1.年老代(Tenured)被写满
2.持久代(Perm)被写满
3.System.gc()被显示调用
4.上一次GC之后Heap的各域分配策略动态变化
Java有了GC同样会出现内存泄露问题
1.静态集合类像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,所有的对象Object也不能被释放,因为他们也将一直被Vector等应用着。
Static Vector v = new Vector();
for (int i = 1; i<100; i++)
{
Object o = new Object();
v.add(o);
o = null;
}
在这个例子中,代码栈中存在Vector 对象的引用 v 和 Object 对象的引用 o 。在 For 循环中,我们不断的生成新的对象,然后将其添加到 Vector 对象中,之后将 o 引用置空。问题是当 o 引用被置空后,如果发生 GC,我们创建的 Object 对象是否能够被 GC 回收呢?答案是否定的。因为, GC 在跟踪代码栈中的引用时,会发现 v 引用,而继续往下跟踪,就会发现 v 引用指向的内存空间中又存在指向 Object 对象的引用。也就是说尽管o 引用已经被置空,但是 Object 对象仍然存在其他的引用,是可以被访问到的,所以 GC 无法将其释放掉。如果在此循环之后, Object 对象对程序已经没有任何作用,那么我们就认为此 Java 程序发生了内存泄漏。
2.各种连接,数据库连接,网络连接,IO连接等没有显示调用close关闭,不被GC回收导致内存泄露。
3.监听器的使用,在释放对象的同时没有相应删除监听器的时候也可能导致内存泄露。
JDK各个版本新特性
jdk1.6新特性
1.Desktop类和SystemTray类
2.使用JAXB2来实现对象与XML之间的映射
3.StAX
4.使用Compiler API
5.轻量级Http Server API
6.插入式注解处理API(Pluggable Annotation Processing API)
7.用Console开发控制台程序
8.对脚本语言的支持
9.Common Annotations
1.Desktop类和SystemTray类
在JDK1.6中,AWT新增加了两个类:Desktop和SystemTray.
前者可以用来打开系统默认浏览器浏览指定的URL,打开系统默认邮件客户端给指定的邮箱发邮件,用默认应用程序打开或编辑文件(比如,用记事本打开以txt为后缀名的文件),用系统默认的打印机打印文档;后者可以用来在系统托盘区创建一个托盘程序.
2.使用JAXB2来实现对象与XML之间的映射
JAXB是Java Architecture for XML Binding的缩写,可以将一个Java对象转变成为XML格式,反之亦然.
我们把对象与关系数据库之间的映射称为ORM,其实也可以把对象与XML之间的映射称为OXM(Object XML Mapping).原来JAXB是Java EE的一部分,在JDK1.6中,SUN将其放到了Java SE中,这也是SUN的一贯做法.JDK1.6中自带的这个JAXB版本是2.0,比起1.0(JSR 31)来,JAXB2(JSR 222)用JDK5的新特性Annotation来标识要作绑定的类和属性等,这就极大简化了开发的工作量.实际上,在Java EE 5.0中,EJB和Web Services也通过Annotation来简化开发工作.另外,JAXB2在底层是用StAX(JSR 173)来处理XML文档.除了JAXB之外,我们还可以通过XMLBeans和Castor等来实现同样的功能.
3.StAX
StAX(JSR 173)是JDK1.6.0中除了DOM和SAX之外的又一种处理XML文档的API.
StAX 的来历:在JAXP1.3(JSR 206)有两种处理XML文档的方法:DOM(Document Object Model)和SAX(Simple API for XML).
JDK1.6.0中的JAXB2(JSR 222)和JAX-WS 2.0(JSR 224)都会用到StAXSun决定把StAX加入到JAXP家族当中来,并将JAXP的版本升级到1.4(JAXP1.4是JAXP1.3的维护版本).JDK1.6里面JAXP的版本就是1.4.
StAX是The Streaming API for XML的缩写,一种利用拉模式解析(pull-parsing)XML文档的API.StAX通过提供一种基于事件迭代器(Iterator)的API让程序员去控制xml文档解析过程,程序遍历这个事件迭代器去处理每一个解析事件,解析事件可以看做是程序拉出来的,也就是程序促使解析器产生一个解析事件然后处理该事件,之后又促使解析器产生下一个解析事件,如此循环直到碰到文档结束符;
SAX也是基于事件处理xml文档,但却是用推模式解析,解析器解析完整个xml文档后,才产生解析事件,然后推给程序去处理这些事件;DOM采用的方式是将整个xml文档映射到一颗内存树,这样就可以很容易地得到父节点和子结点以及兄弟节点的数据,但如果文档很大,将会严重影响性能.
4.使用Compiler API
现在我 们可以用JDK1.6 的Compiler API(JSR 199)去动态编译Java源文件,Compiler API结合反射功能就可以实现动态的产生Java代码并编译执行这些代码,有点动态语言的特征.
这个特性对于某些需要用到动态编译的应用程序相当有用,比如JSP Web Server,当我们手动修改JSP后,是不希望需要重启Web Server才可以看到效果的,这时候我们就可以用Compiler API来实现动态编译JSP文件,当然,现在的JSP Web Server也是支持JSP热部署的,现在的JSP Web Server通过在运行期间通过Runtime.exec或ProcessBuilder来调用javac来编译代码,这种方式需要我们产生另一个进程去做编译工作,不够优雅容易使代码依赖与特定的操作系统;Compiler API通过一套易用的标准的API提供了更加丰富的方式去做动态编译,是跨平台的.
5.轻量级Http Server API
JDK1.6 提供了一个简单的Http Server API,据此我们可以构建自己的嵌入式Http Server,它支持Http和Https协议,提供了HTTP1.1的部分实现,没有被实现的那部分可以通过扩展已有的Http Server API来实现,程序员自己实现HttpHandler接口,HttpServer会调用HttpHandler实现类的回调方法来处理客户端请求,在这里,我们把一个Http请求和它的响应称为一个交换,包装成HttpExchange类,HttpServer负责将HttpExchange传给HttpHandler实现类的回调方法.
6.插入式注解处理API(Pluggable Annotation Processing API)
插入式注解处理API(JSR 269)提供一套标准API来处理Annotations(JSR 175)
实际上JSR 269不仅仅用来处理Annotation,我觉得更强大的功能是它建立了Java 语言本身的一个模型,它把method,package,constructor,type,variable, enum,annotation等Java语言元素映射为Types和Elements(两者有什么区别?),从而将Java语言的语义映射成为对象,我们可以在javax.lang.model包下面可以看到这些类. 我们可以利用JSR 269提供的API来构建一个功能丰富的元编程(metaprogramming)环境.
JSR 269用Annotation Processor在编译期间而不是运行期间处理Annotation,Annotation Processor相当于编译器的一个插件,称为插入式注解处理.如果Annotation Processor处理Annotation时(执行process方法)产生了新的Java代码,编译器会再调用一次Annotation Processor,如果第二次处理还有新代码产生,就会接着调用Annotation Processor,直到没有新代码产生为止.每执行一次process()方法被称为一个"round",这样整个Annotation processing过程可以看作是一个round的序列.
JSR 269主要被设计成为针对Tools或者容器的API. 举个例子,我们想建立一套基于Annotation的单元测试框架(如TestNG),在测试类里面用Annotation来标识测试期间需要执行的测试方法.
7.用Console开发控制台程序
JDK1.6中提供了java.io.Console 类专用来访问基于字符的控制台设备.你的程序如果要与Windows下的cmd或者Linux下的Terminal交互,就可以用Console类代劳.但我们不总是能得到可用的Console,一个JVM是否有可用的Console依赖于底层平台和JVM如何被调用.如果JVM是在交互式命令行(比如Windows的cmd)中启动的,并且输入输出没有重定向到另外的地方,那么就可以得到一个可用的Console实例.
8.对脚本语言的支持
如: ruby,groovy,javascript
9.Common Annotations
Common annotations原本是Java EE 5.0(JSR 244)规范的一部分,现在SUN把它的一部分放到了Java SE 6.0中.
随着Annotation元数据功能(JSR 175)加入到Java SE 5.0里面,很多Java 技术(比如EJB,Web Services)都会用Annotation部分代替XML文件来配置运行参数(或者说是支持声明式编程,如EJB的声明式事务),如果这些技术为通用目的都单独定义了自己的Annotations,显然有点重复建设,,为其他相关的Java技术定义一套公共的Annotation是有价值的,可以避免重复建设的同时,也保证Java SE和Java EE 各种技术的一致性.
下面列举出Common Annotations 1.0里面的10个Annotations Common Annotations Annotation Retention Target Description Generated Source ANNOTATION_TYPE,CONSTRUCTOR,FIELD,LOCAL_VARIABLE,METHOD,PACKAGE,PARAMETER,TYPE 用于标注生成的源代码Resource Runtime TYPE,METHOD,FIELD用于标注所依赖的资源,容器据此注入外部资源依赖,有基于字段的注入和基于setter方法的注入两种方式Resources Runtime TYPE同时标注多个外部依赖,容器会把所有这些外部依赖注入PostConstruct Runtime METHOD标注当容器注入所有依赖之后运行的方法,用来进行依赖注入后的初始化工作,只有一个方法可以标注为PostConstruct PreDestroy Runtime METHOD当对象实例将要被从容器当中删掉之前,要执行的回调方法要标注为PreDestroy RunAs Runtime TYPE用于标注用什么安全角色来执行被标注类的方法,这个安全角色和Container的Security角色一致的.RolesAllowed Runtime TYPE,METHOD用于标注允许执行被标注类或方法的安全角色,这个安全角色和Container的Security角色一致的PermitAll Runtime TYPE,METHOD允许所有角色执行被标注的类或方法DenyAll Runtime TYPE,METHOD不允许任何角色执行被标注的类或方法,表明该类或方法不能在Java EE容器里面运行DeclareRoles Runtime TYPE用来定义可以被应用程序检验的安全角色,通常用isUserInRole来检验安全角色.
jdk7新特性:
1 对集合类的语言支持;
2 自动资源管理;
3 改进的通用实例创建类型推断;
4 数字字面量下划线支持;
5 switch中使用string;
6 二进制字面量;
7 简化可变参数方法调用。
1 对集合类的语言支持 (没有实现)
Java将包含对创建集合类的第一类语言支持。这意味着集合类的创建可以像Ruby和Perl那样了。
原本需要这样:
List<String> list = new ArrayList<String>();
list.add("item");
String item = list.get(0);
Set<String> set = new HashSet<String>();
set.add("item");
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("key", 1);
int value = map.get("key");
现在你可以这样:
List<String> list = ["item"];
String item = list[0];
Set<String> set = {"item"};
Map<String, Integer> map = {"key" : 1};
int value = map["key"];
这些集合是不可变的。
2 自动资源管理
Java中某些资源是需要手动关闭的,如InputStream,Writes,Sockets,Sql classes等。这个新的语言特性允许try语句本身申请更多的资源,
这些资源作用于try代码块,并自动关闭。
这个:
BufferedReader br = new BufferedReader(new FileReader(path));
try {
return br.readLine();
} finally {
br.close();
}
变成了这个:
try (BufferedReader br = new BufferedReader(new FileReader(path)) {
return br.readLine();
}
你可以定义关闭多个资源:
try (
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(dest))
{
// code
}
为了支持这个行为,所有可关闭的类将被修改为可以实现一个Closable(可关闭的)接口。
3 增强的对通用实例创建(diamond)的类型推断
类型推断是一个特殊的烦恼,下面的代码:
Map<String, List<String>> anagrams = new HashMap<String, List<String>>();
通过类型推断后变成:
Map<String, List<String>> anagrams = new HashMap<>();
这个<>被叫做diamond(钻石)运算符,这个运算符从引用的声明中推断类型。
4 数字字面量下划线支持
很长的数字可读性不好,在Java 7中可以使用下划线分隔长int以及long了,如:
int one_million = 1_000_000;
运算时先去除下划线,如:1_1 * 10 = 110,120 – 1_0 = 110
5 switch中使用string
以前你在switch中只能使用number或enum。现在你可以使用string了:
String s = ...
switch(s) {
case "quux":
processQuux(s);
// fall-through
case "foo":
case "bar":
processFooOrBar(s);
break;
case "baz":
processBaz(s);
// fall-through
default:
processDefault(s);
break;
}
6 二进制字面量
由于继承C语言,Java代码在传统上迫使程序员只能使用十进制,八进制或十六进制来表示数(numbers)。
由于很少的域是以bit导向的,这种限制可能导致错误。你现在可以使用0b前缀创建二进制字面量:
int binary = 0b1001_1001;
现在,你可以使用二进制字面量这种表示方式,并且使用非常简短的代码,可将二进制字符转换为数据类型,如在byte或short。
byte aByte = (byte)0b001;
short aShort = (short)0b010;
7 简化的可变参数调用
当程序员试图使用一个不可具体化的可变参数并调用一个*varargs* (可变)方法时,编辑器会生成一个“非安全操作”的警告。
JDK 7将警告从call转移到了方法声明(methord declaration)的过程中。这样API设计者就可以使用vararg,因为警告的数量大大减少了。JDK8新特性(2014年初)(LTS版本)
1、Lambda表达式
2、函数式编程
3、接口可以添加默认方法和静态方法,也就是定义不需要实现类实现的方法
4、方法引用
5、重复注解,同一个注解可以使用多次
6、引入Optional来避免空指针
7、引入Streams相关的API
8、引入新的Date/Time相关的API
9、新增jdeps命令行,来分析类、目录、jar包的类依赖层级关系
10、JVM使用MetaSpace代替了永久代(PermGen Space)
重要特性:Lambda表达式、函数式接口、方法引用、Stream流式API、采用MetaSpace代替了永久代(PermGen Space)
https://blogs.oracle.com/javamagazine/post/java-garbage-collectors-evolution
JDK9新特性(2017年9月)
1、接口方法可以使用private来修饰
2、设置G1为JVM默认垃圾收集器
3、支持http2.0和websocket的API
重要特性:主要是API的优化,如支持HTTP2的Client API、JVM采用G1为默认垃圾收集器
1、集合加强
jdk9为所有集合(List/Set/Map)都增加了of和copyOf方法,用来创建不可变集合,即一旦创建就无法再执行添加、删除、替换、排序等操作,否则将报java.lang.UnsupportedOperationException异常。
一般在特定场景下用还是可以的,不过如果引用了guava库的话推荐还是使用guava把hhhh,例子如下:
2、私有接口方法
jdk8提供了接口的默认方法(default)和静态方法,打破了之前接口只能定义方法而不能存在行为。
jdk9则是允许接口定义私有方法,私有方法可以作为通用方法放在默认方法中调用,不过实际中并无多大用处,至少对我来说。
3、垃圾收集机制
jdk9把G1作为默认的垃圾收集器实现,替换了jdk7和jdk8的默认垃圾收集器实现:Parallel Scavenge(新生代)+Parallel Old(老年代)。
4、I/O流加强
java.io.InputStream 中增加了新的方法来读取和复制 InputStream 中包含的数据:
readAllBytes:读取 InputStream 中的所有剩余字节
readNBytes: 从 InputStream 中读取指定数量的字节到数组中
transferTo:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中
5、JShell工具
jdk9引入了jshell这个交互性工具,让Java也可以像脚本语言一样来运行,可以从控制台启动 jshell ,在 jshell 中直接输入表达式并查看其执行结果。
当需要测试一个方法的运行效果,或是快速的对表达式进行求值时,jshell 都非常实用。JDK10新特性(2018年3月)
1、局部变量类型推断,类似JS可以通过var来修饰局部变量,编译之后会推断出值的真实类型
2、并行Full GC,来优化G1的延迟
3、允许在不执行全局VM安全点的情况下执行线程回调,可以停止单个线程,而不需要停止所有线程或不停止线程
重要特性:通过var关键字实现局部变量类型推断,使Java语言变成弱类型语言、JVM的G1垃圾回收由单线程改成多线程并行处理,降低G1的停顿时间
1、局部变量类型推断
局部变量类型推断可以说是jdk10中最值得注意的特性,这是Java语言开发人员为了简化Java应用程序的编写而采取的又一步,举个例子:
原先我们需要这么定义一个list
使用局部类型推断var关键词定义
不过局部变量类型推断仅仅适用在:
有初始化值的局部变量
增强 for 循环中的索引
传统 for 循环中声明的局部变量
Oracle 的 Java 团队申明,以下不支持局部变量类型推断:
方法参数
构造函数参数
方法返回类型
字段
catch 代码块(或任何其他类型的变量声明)
2、线程本地握手
jdk10将引入一种在线程上执行回调的新方法,因此这将会很方便能停止单个线程而不是停止全部线程或者一个都不停。说实话并不是很懂是什么意思...
3、GC改进和内存管理
jdk10中有2个JEP专门用于改进当前的垃圾收集元素。
第一个垃圾收集器接口是(JEP 304),它将引入一个纯净的垃圾收集器接口,以帮助改进不同垃圾收集器的源代码隔离。
预定用于Java 10的第二个JEP是针对G1的并行完全GC(JEP 307),其重点在于通过完全GC并行来改善G1最坏情况的等待时间。
G1是Java 9中的默认GC,并且此JEP的目标是使G1平行。JDK11新特性(2018年9月)(LTS版本)
1、ZGC,ZGC可以看做是G1之上更细粒度的内存管理策略。由于内存的不断分配回收会产生大量的内存碎片空间,因此需要整理策略防止内存空间碎片化,在整理期间需要将对于内存引用的线程逻辑暂停,这个过程被称为"Stop the world"。只有当整理完成后,线程逻辑才可以继续运行。(并行回收)
2、Flight Recorder(飞行记录器),基于OS、JVM和JDK的事件产生的数据收集框架
3、对Stream、Optional、集合API进行增强
重要特性:对于JDK9和JDK10的完善,主要是对于Stream、集合等API的增强、新增ZGC垃圾收集器
1、字符串加强

2、HttClient Api
这是 Java 9 开始引入的一个处理 HTTP 请求的的孵化 HTTP Client API,该 API 支持同步和异步,而在 Java 11 中已经为正式可用状态,你可以在java.net包中找到这个 Api
3、用于 Lambda 参数的局部变量语法
用于 Lambda 参数的局部变量语法简单来说就是支持类型推导:

4、ZGC
从JDK 9开始,JDK使用G1作为默认的垃圾回收器。G1可以说是GC的一个里程碑,G1之前的GC回收,还是基于固定的内存区域,而G1采用了一种"细粒度"的内存管理策略,不在固定的区分内存区域属于surviors、eden、old,而我们不需要再去对于年轻代使用一种回收策略,老年代使用一种回收策略,取而代之的是一种整体的内存回收策略。这种回收策略在我们当下cpu、内存、服务规模都越来越大的情况下提供了更好的表现,而这一代ZGC更是有了突破性的进步。
从原理上来理解,ZGC可以看做是G1之上更细粒度的内存管理策略。由于内存的不断分配回收会产生大量的内存碎片空间,因此需要整理策略防止内存空间碎片化,在整理期间需要将对于内存引用的线程逻辑暂停,这个过程被称为"Stop the world"。只有当整理完成后,线程逻辑才可以继续运行,一般而言,主要有如下几种方式优化"Stop the world":
-
使用多个线程同时回收(并行回收)
-
回收过程分为多次停顿(增量回收)
-
在程序运行期间回收,不需要停顿或只停顿很短时间(并发回收)
-
只回收内存而不整理内存
ZGC主要采用的是并发回收的策略,相较于G1 ZGC最主要的提升是使用Load Barrier技术实现,引用R大对于ZGC的评价:
与标记对象的传统算法相比,ZGC在指针上做标记,在访问指针时加入Load Barrier(读屏障),比如当对象正被GC移动,指针上的颜色就会不对,这个屏障就会先把指针更新为有效地址再返回,也就是,永远只有单个对象读取时有概率被减速,而不存在为了保持应用与GC一致而粗暴整体的Stop The World。
JDK12新特性(2019年3月)
1、Shenandoah GC,新增的GC算法
2、switch 表达式语法扩展,可以有返回值
3、G1收集器的优化,将GC的垃圾分为强制部分和可选部分,强制部分会被回收,可选部分可能不会被回收,提高GC的效率
重要特性:switch表达式语法扩展、G1收集器优化、新增Shenandoah GC垃圾回收算法
1、Switch Expressions
这是一个为开发者准备的特性,我们可以利用具体代码快速了解一下,下面是传统 statement 形式的 switch 语法:
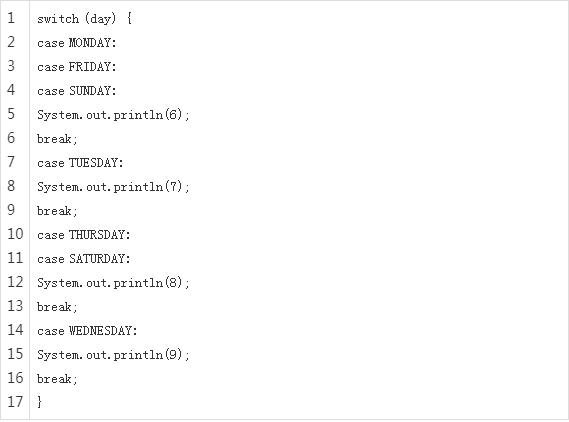
如果有编码经验,你一定知道,switch 语句如果漏写了一个 break,那么逻辑往往就跑偏了,这种方式既繁琐,又容易出错。
如果换成 switch 表达式,Pattern Matching 机制能够自然地保证只有单一路径会被执行,请看下面的代码示例:

更进一步,下面的表达式,为我们提供了优雅地表达特定场合计算逻辑的方式

Switch Expressions 或者说起相关的 Pattern Matching 特性,为我们提供了勾勒出了 Java 语法进化的一个趋势,将开发者从复杂繁琐的低层次抽象中逐渐解放出来,以更高层次更优雅的抽象,既降低代码量,又避免意外编程错误的出现,进而提高代码质量和开发效率。
2、Shenandoah GC
新增了一个名为 Shenandoah 的 GC 算法,通过与正在运行的 Java 线程同时进行 evacuation 工作来减少 GC 暂停时间。
使用 Shenandoah 的暂停时间与堆大小无关,这意味着无论堆是 200 MB 还是 200 GB,都将具有相同的暂停时间。
JDK13新特性(2019年9月)
1、Socket的底层实现优化,引入了NIO;
2、switch表达式增加yield关键字用于返回结果,作用类似于return,如果没有返回结果则使用break;
3、ZGC优化,将标记长时间空闲的堆内存空间返还给操作系统,保证堆大小不会小于配置的最小堆内存大小,如果堆最大和最小内存大小设置一样,则不会释放内存还给操作系统;
4、引入了文本块,可以使用"""三个双引号表示文本块,文本块内部就不需要使用换行的转义字符;
重要特性:ZGC优化,释放内存还给操作系统、socket底层实现引入NIO
JDK13于9月17日正式发布。目前该版本包含的特性已经全部固定,主要包含以下五个:

下面来逐一介绍下这五个重要的特性。
Dynamic CDS Archives
这一特性是在JEP310:Application Class-Data Sharing基础上扩展而来的,Dynamic CDS Archives中的CDS指的就是Class-Data Sharing。
那么,这个JEP310是个啥东西呢?
我们知道在同一个物理机/虚拟机上启动多个JVM时,如果每个虚拟机都单独装载自己需要的所有类,启动成本和内存占用是比较高的。所以Java团队引入了CDS的概念,通过把一些核心类在每个JVM间共享,每个JVM只需要装载自己的应用类,启动时间减少了,另外核心类是共享的,所以JVM的内存占用也减少了。
CDS 只能作用于 Boot Class Loader 加载的类,不能作用于 App Class Loader 或者自定义的 Class Loader 加载的类。
在 Java 10 中,则将 CDS 扩展为 AppCDS,顾名思义,AppCDS 不止能够作用于 Boot Class Loader了,App Class Loader 和自定义的 Class Loader 也都能够起作用,大大加大了 CDS 的适用范围。也就说开发自定义的类也可以装载给多个JVM共享了。
Java 10中包含的JEP310的通过跨不同Java进程共享公共类元数据来减少了内存占用和改进了启动时间。
但是,JEP310中,使用AppCDS的过程还是比较复杂的,需要有三个步骤:

这一次的JDK 13中的JEP 350 ,在JEP310的基础上,又做了一些扩展。允许在Java应用程序执行结束时动态归档类,归档类将包括默认的基础层 CDS(class data-sharing)存档中不存在的所有已加载的应用程序类和库类。
也就是说,在Java 13中再使用AppCDS的时候,就不在需要这么复杂了。
ZGC: Uncommit Unused Memory
在讨论这个问题之前,想先问一个问题,JVM的GC释放的内存会还给操作系统吗?
GC后的内存如何处置,其实是取决于不同的垃圾回收器的。因为把内存还给OS,意味着要调整JVM的堆大小,这个过程是比较耗费资源的。
在JDK 11中,Java引入了ZGC,这是一款可伸缩的低延迟垃圾收集器,但是当时只是实验性的。并且,ZGC释放的内存是不会还给操作系统的。

而在Java 13中,JEP 351再次对ZGC做了增强,本次 ZGC 可以将未使用的堆内存返回给操作系统。之所以引入这个特性,是因为如今有很多场景中内存是比较昂贵的资源,在以下情况中,将内存还给操作系统还是很有必要的:
-
1、那些需要根据使用量付费的容器
-
2、应用程序可能长时间处于空闲状态并与许多其他应用程序共享或竞争资源的环境。
-
3、应用程序在执行期间可能有非常不同的堆空间需求。例如,启动期间所需的堆可能大于稍后在稳定状态执行期间所需的堆。
Reimplement the Legacy Socket API
使用易于维护和调试的更简单、更现代的实现替换 java.net.Socket 和 java.net.ServerSocket API。
java.net.Socket和java.net.ServerSocket的实现非常古老,这个JEP为它们引入了一个现代的实现。现代实现是Java 13中的默认实现,但是旧的实现还没有删除,可以通过设置系统属性jdk.net.usePlainSocketImpl来使用它们。
运行一个实例化Socket和ServerSocket的类将显示这个调试输出。这是默认的(新的).

上面输出的sun.nio.ch.NioSocketImpl就是新提供的实现。
如果使用旧的实现也是可以的(指定参数jdk.net.usePlainSocketImpl):

上面的结果中,旧的实现java.net.PlainSocketImpl被用到了。
Switch Expressions (Preview)
在JDK 12中引入了Switch表达式作为预览特性。JEP 354修改了这个特性,它引入了yield语句,用于返回值。这意味着,switch表达式(返回值)应该使用yield, switch语句(不返回值)应该使用break。
在以前,我们想要在switch中返回内容,还是比较麻烦的,一般语法如下:

在JDK13中使用以下语法:

或者

在这之后,switch中就多了一个关键字用于跳出switch块了,那就是yield,他用于返回一个值。和return的区别在于:return会直接跳出当前循环或者方法,而yield只会跳出当前switch块。
Text Blocks (Preview)
在JDK 12中引入了Raw String Literals特性,但在发布之前就放弃了。这个JEP在引入多行字符串文字(text block)在意义上是类似的。
text block,文本块,是一个多行字符串文字,它避免了对大多数转义序列的需要,以可预测的方式自动格式化字符串,并在需要时让开发人员控制格式。
我们以前从外部copy一段文本串到Java中,会被自动转义,如有一段以下字符串:

将其复制到Java的字符串中,会展示成以下内容:

使用"""作为文本块的开始符合结束符,在其中就可以放置多行的字符串,不需要进行任何转义。看起来就十分清爽了。
如常见的SQL语句:

看起来就比较直观,清爽了。
JDK13中包含的5个特性,能够改变开发者的编码风格的主要有Text Blocks和Switch Expressions两个新特性,但是这两个特性还处于预览阶段。
而且,JDK13并不是LTS(长期支持)版本,如果你正在使用Java 8(LTS)或者Java 11(LTS),暂时可以不必升级到Java 13.
JDK14新特性(2020年3月)
1、instanceof类型匹配语法简化,可以直接给对象赋值,如if(obj instanceof String str),如果obj是字符串类型则直接赋值给了str变量;
2、引入record类,类似于枚举类型,可以向Lombok一样自动生成构造器、equals、getter等方法;
3、NullPointerException打印优化,打印具体哪个方法抛的空指针异常,避免同一行代码多个函数调用时无法判断具体是哪个函数抛异常的困扰,方便异常排查;
JDK15新特性(2020年9月)
1、隐藏类 hidden class;
2、密封类 sealed class,通过sealed关键字修饰抽象类限定只允许指定的子类才可以实现或继承抽象类,避免抽象类被滥用;
JDK16新特性(2021年3月)
1、ZGC性能优化
2、instanceof模式匹配
3、record的引入
JDK16相当于是将JDK14、JDK15的一些特性进行了正式引入。
JDK17新特性(2021年9月)(LTS版本)
1、正式引入密封类sealed class,限制抽象类的实现;
2、统一日志异步刷新,先将日志写入缓存,然后再异步刷新;
虽然JDK17也是一个LTS版本,但是并没有像JDK8和JDK11一样引入比较突出的特性,主要是对前几个版本的整合和完善。
删除实验性的提前(AOT)和即时(JIT)编译器:这些编译器自推出以来很少使用,维护它们的工作量大,因此被移除以减少维护负担。
弃用安全管理器和Applet API:安全管理器多年来不是保护客户端Java代码的主要方法,而Applet API已被淘汰多年,没有继续保留的理由。
特定于上下文的反序列化过滤器:允许应用程序使用JVM范围的过滤器工厂配置特定于上下文和动态选择的反序列化过滤器,以提高安全性。
对NullPointerExceptions的优化:现在可以更准确地显示NullPointerException发生的精确位置,而不是仅显示行号。
Sealed classes:允许限制类的继承和实现,有助于保证API类不被未授权的修改或扩展。
Pattern matching for instanceof:允许在switch语句中使用模式匹配来测试一个对象是否是某个类的实例。
Strong encapsulation of JDK internals:通过使外部代码无法访问JDK内部API来提高安全性和可维护性。
Foreign function and memory API:提供了与非Java代码和内存交互的标准API,使得与本地库和系统集成更加容易。
改进的字符串字面量和新的数学运算符:如min和max运算符,提供了更快捷的计算方式。
模块化:Java 17引入了模块系统,将Java分成了若干个可以独立部署和运行的模块,提高了启动速度和硬件资源利用率。
内联类:这种类可以被定义为常量并直接嵌入到其他类或方法中,减少了运行时的内存占用和提高性能。
语言特性增强:如密封的类和接口(正式版),增强了Java编程语言的安全性和可维护性。JDK 17更新了包括14个特性,具体如下表所示:

图片
306:恢复始终严格模式(Always-Strict)的浮点语义
Restore Always-StrictFloating-Point Semantics0
恢复始终执行严格模式的浮点定义,修复25年前英特尔的浮点指令存在的一些问题;
356:增强型伪随机数发生器
EnhancedPseudo-Random Number Generators
增加了伪随机数相关的类和接口来让开发者使用stream流进行操作,
代码语言:javascript
复制
RandomGenerator generator = RandomGeneratorFactory.all()
.filter(RandomGeneratorFactory::isJumpable)
.filter(factory -> factory.stateBits() > 128)
.findAny()
.map(RandomGeneratorFactory::create)
// if you need a `JumpableGenerator`:
// .map(JumpableGenerator.class::cast)
.orElseThrow();- RandomGenerator
- RandomGeneratorFactory
382:新增macOS渲染管道
New macOS RenderingPipeline
391:支持将JDK移植到macOS或AArch64
macOS/AArch64 Port
398:弃用待移除的Applet API
Deprecate the AppletAPI for Removal
弃用、删除标准 Java API 的这些类和接口:
弃用或删除任何引用上述类和接口的 API 元素,包括以下中的方法和字段:
java.beans.Beansjavax.swing.RepaintManagerjavax.naming.Contextjava.applet.Appletjava.applet.AppletStubjava.applet.AppletContextjava.applet.AudioClipjavax.swing.JAppletjava.beans.AppletInitializer
403:强封装JDK内部API
Strongly EncapsulateJDK Internals
406:switch模式匹配进入预览(Preview)阶段
Pattern Matching forswitch (Preview)
引入switch模式匹配的preview版本
代码语言:javascript
复制
// Old code
if (o instanceof String) {
String s = (String)o;
... use s ...
}
// New code
if (o instanceof String s) {
... use s ...
}switch的写法:
代码语言:javascript
复制
static String formatterPatternSwitch(Object o) {
return switch (o) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> o.toString();
};
}407:移除RMI(远程方法调用)激活机制
Remove RMI Activation
409:密封类
Sealed Classes
密封类是由JEP 360提出的,并在JDK 15中作为预览功能提供。它们由JEP 397再次提出并进行了改进,并作为预览功能在JDK 16中提供。该JEP建议在JDK17中完成密封类,与JDK 16没有任何变化。
410:移除实验性AOT和JIT编译器
Remove theExperimental AOT and JIT Compiler
411:弃用待移除的安全管理器(Security Manager)
Deprecate theSecurity Manager for Removal
弃用安全管理器,在后续版本中移除。安全管理器可追溯到Java 1.0。多年来,它一直不是保护客户端Java代码的主要手段,也很少用于保护服务器端代码。为了推动Java向前发展,Oracle打算弃用安全管理器,以便与旧Applet API(JEP 398)一起删除。
412:外部函数和内存API(孵化器)孵化阶段
Foreign Function& Memory API (Incubator)
Java程序可以通过该API与Java运行时之外的代码和数据进行互操作。通过有效调用外部函数(即JVM之外的代码),以及安全地访问外部内存(即不由JVM管理的内存),API使Java程序能够调用本地库和处理本地数据,而没有JNI。[关于JDK17新特性开发应用,关注公众号Java精选,后续文章更新]
414:Vector API(第二孵化器)第二孵化阶段
Vector API (SecondIncubator)
引入一个API来表达向量计算,这些计算在运行时可靠地编译为支持的CPU架构上的最佳向量指令,从而实现优于等效标量计算的性能。
415:上下文特定的反序列化过滤器
Context-SpecificDeserialization Filters
允许应用程序通过JVM范围的过滤器工厂配置特定于上下文和动态选择的反序列化过滤器,该工厂被调用以为每个单独的反序列化操作选择一个过滤器。
文特定的反序列化过滤器**
Context-SpecificDeserialization Filters
允许应用程序通过JVM范围的过滤器工厂配置特定于上下文和动态选择的反序列化过滤器,该工厂被调用以为每个单独的反序列化操作选择一个过滤器。